
在大数据背景下,传统的管理与决策方法研究正从以管理流程为主的线性范式,逐渐向以数据为中心的扁平化范式转变。数据资源的采集、清洗、建模、特征提取、分类回归和知识发现等,为实现数据驱动的管理决策方法提供了重要基础技术支撑。在移动互联网开放环境下,受数据源的多样性、数据内涵的复杂性等因素影响,数据的表现形式呈现多模态、跨模态特性,即,数据中包含文字、信息表、图像、视频等互相对应或互相关联的多种模态信息,并包含多媒体的高层语义信息与知识关联,同时又包含模态间的差异性和“语义鸿沟”。因此,如何充分且有效地挖掘各种模态数据中潜在的信息和价值,并进行多模态、跨模态、多层次的关联知识发现,建立数据的跨模态高效快速检索模型与方法,已成为当前数据驱动的管理与决策研究的重要基础课题。
跨模态哈希(Cross-Modal Hashing)学习方法是近年来兴起的一种数据挖掘和检索技术,已在文本、图像等多模态数据分析方面取得了成功,受到广泛关注,目前研究者们对于跨模态哈希学习方法正进行更深入的探索和研究。但是经典跨模态哈希学习方法在理论方法和应用中仍面临诸多挑战。例如,如何充分挖掘数据多标签间的高阶语义信息关联,利用标签信息挖掘隐含语义信息,以跨越不同模态间“语义鸿沟”;如何在跨模态哈希学习和哈希函数学习中保持样本特征的表征一致性和相似性,以提升哈希特征在跨模态检索中的算法性能。这些科学问题有待于进一步探索和解决。
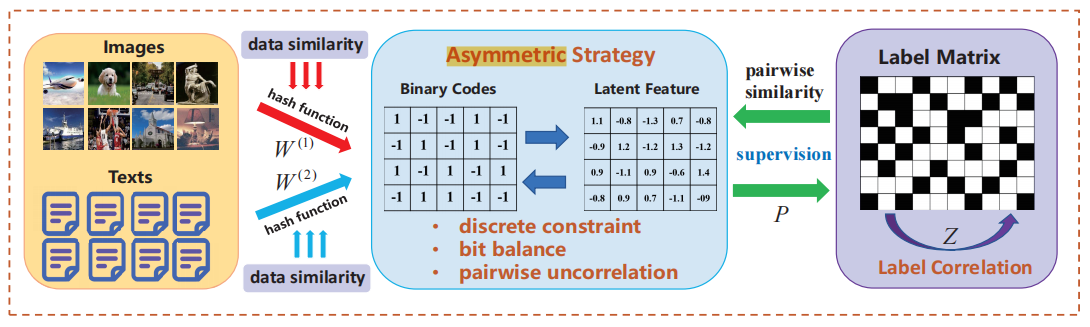
图1:自适应标签关联跨模态哈希方法(ALECH)框架示意图
自适应标签关联跨模态哈希方法(Adaptive Label correlation based asymmEtric Cross-modal Hashing,ALECH)是最近我院机器学习与智能决策中心团队提出的一种新型跨模态数据挖掘与检索方法。该方法采用两步法实现哈希学习过程,包括哈希码学习(Hash Codes Learning)和哈希函数学习(Hash Functions Learning),通过自适应标签关联的哈希码学习,ALECH挖掘到多模态数据的高阶语义关联信息,充分提取数据中隐含特征信息,并通过不对称内积哈希学习,保持多模态数据特征的表征一致性和相似性,构建跨模态哈希码学习非凸优化模型。在此工作中,我院机器学习与智能决策中心团队提出了自适应标签关联跨模态哈希方法的技术原型框架(图1)。为求解跨模态哈希码学习的非凸优化模型,课题组引入交替优化策略,采用迭代优化获得哈希码学习结果,并提出一种可保持多模态数据特征类内相似性的哈希函数学习方法,以实现高效自适应标签关联的跨模态检索。
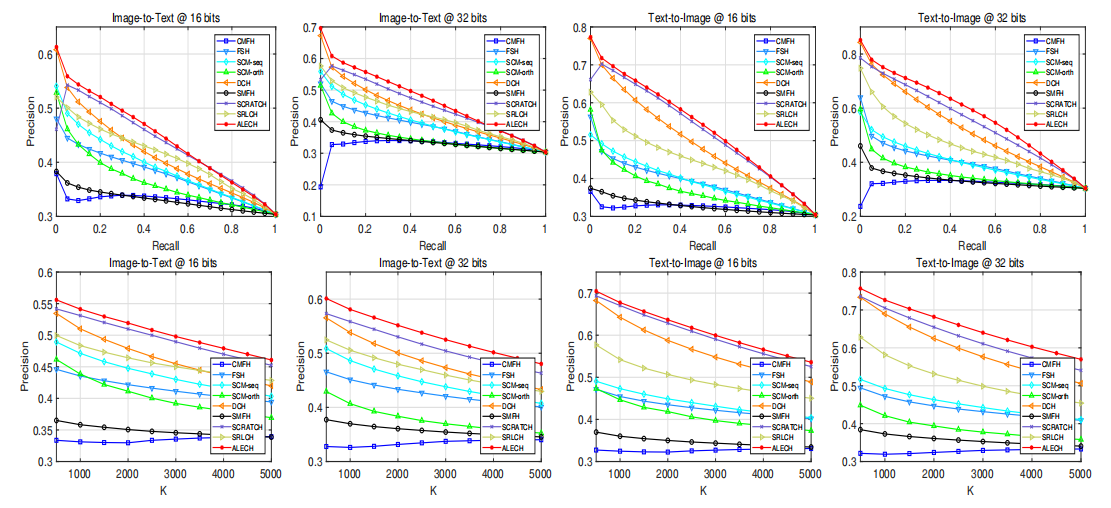
图2: ALECH和Baselines方法在IAPR TC-12上的精度召回(PR)曲线图
为验证ALECH方法的有效性,课题组在MIRFlickr-25K, IAPR TC-12,NUS-WIDE等数据集上做了对比实验。实验表明,ALECH在数据集上与SOTA方法相比具有更优的性能(图2)。在CIFAR-10图像数据集上的检索实验表明,ALECH的图像检索结果准确(图3)。

图3:ALECH在CIFAR-10图像数据集上的检索实验结果
该工作以“Adaptive label correlation based asymmetric discrete hashing for cross-modal retrieval”为题,近日在《IEEE Transactions on Knowledge and Data Engineering》(TKDE,知识和数据工程IEEE汇刊)在线发表(DOI:10.1109/TKDE.2021.3102119)。TKDE是中国自动化学会(CAA)和中国计算机学会(CCF)等多个学会共同推荐的数据挖掘领域A类国际顶尖学术期刊,南大A类学术期刊。我院机器学习与智能决策中心李华雄副教授为该论文第一和通讯作者,章超研究生,陈春林教授,我校计算机科学与技术系高阳教授和南京理工大学计算机科学与工程学院贾修一副教授为该论文合作作者。这是我院首次在IEEE TKDE期刊上发表研究成果。
该研究工作得到了国家自然科学基金重点项目(71732003)、国家重点研发计划项目2018YFB1402600、国家自然科学基金项目(62073160, 71671086, 61773208)等项目的资助。
附论文链接地址:
http://doi.org/10.1109/TKDE.2021.3102119
